I started writing automated tests a decade ago, around 2013. At that time, QUnit was the popular testing framework for JavaScript. Soon after that, Jasmine and Karma took over the front-end scene, while Mocha, Chai, and Sinon were the preferred choices for Node.js. On the other hand, regarding end-to-end full system tests, Selenium was still reigning supreme.
Nowadays, I'm using a totally different toolkit. In this post, I'll describe all the tools and practices I currently use to cover automated functional testing for an entire web application. Here's a quick summary of everything we're going to address:
- Testing tools overview
- Unit testing
- API endpoints testing
- End-to-end system testing
- UI components testing
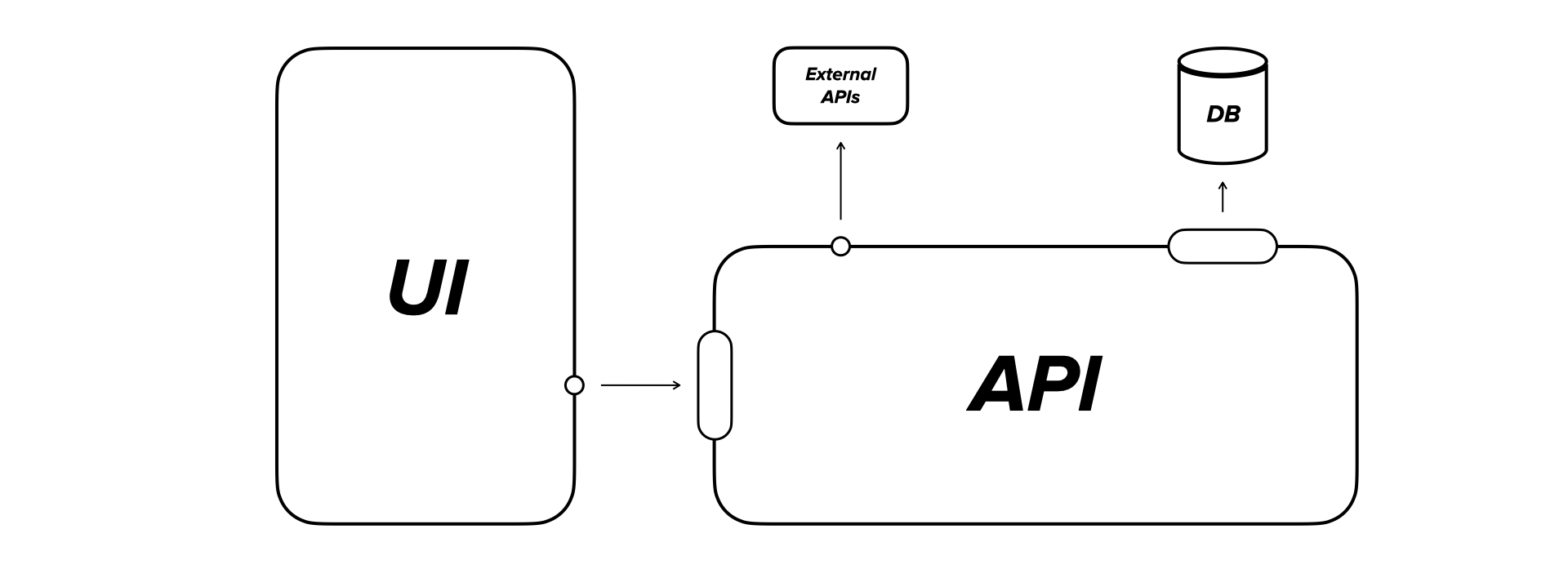
The testing approaches detailed in this article address a typical medium-sized project containing web UIs connected to a RESTful API, which in turn consumes other external APIs.
But before jumping to specific testing approaches, let's have a quick overview of the toolbox I'm currently working with.
Testing tools overview
It's worth mentioning that the ecosystem I'm working with at the moment includes React/ReactNative/Node.js/TypeScript, but all the listed tools are framework agnostic, therefore they can be used with any or no framework at all.
Jest
The tool I use most during testing is Jest, as it helps me test code that would eventually run in a browser, on Node.js, or a JavaScript engine inside a native thread like React Native.
The reason for using Jest is that it's the first JavaScript test runner that's very easy to set up. Additionally, it provides countless useful features:
- out-of-the-box assertion library, mocking utilities, and code coverage;
- built-in watch mode, re-running the tests only when their dependencies have changed;
- powerful CLI, allowing to execute tests based on pattern matching;
- parallel test execution in isolated processes, with the option to run them serially.
Supertest
When it comes to API endpoints testing, I turn to Supertest, a utility that enables black-box tests for an HTTP server like Node.js. The neat thing about Supertest is that it allows us to make actual HTTP requests as handled by the application and assert the response.
Supertest has its own assertions for the HTTP layer, but we can also pair it with Jest for more advanced assertions, stubbing, or mocking.
Cypress
Switching to user interfaces, Cypress is the go-to option for me. The power of Cypress is that it runs tests directly within a real browser, making it suitable for end-to-end system tests.
However, Cypress is not restricted to fully integrated tests. Since v9, it also supports isolated UI components testing with real browser integration.
Testing library
For UI components that don't require a real browser or React hooks, on the other hand, I use Jest + Testing Library.
It's worth mentioning that Testing Library is not a testing framework per-se. When used with Jest, it renders components in jsdom, a virtual DOM implementation that runs on Node.js. This means that we cannot perform DOM layout calculations or access browser APIs like WebStorage, scroll handlers, and more. However, the benefits revolve around execution speed and lightweightness.
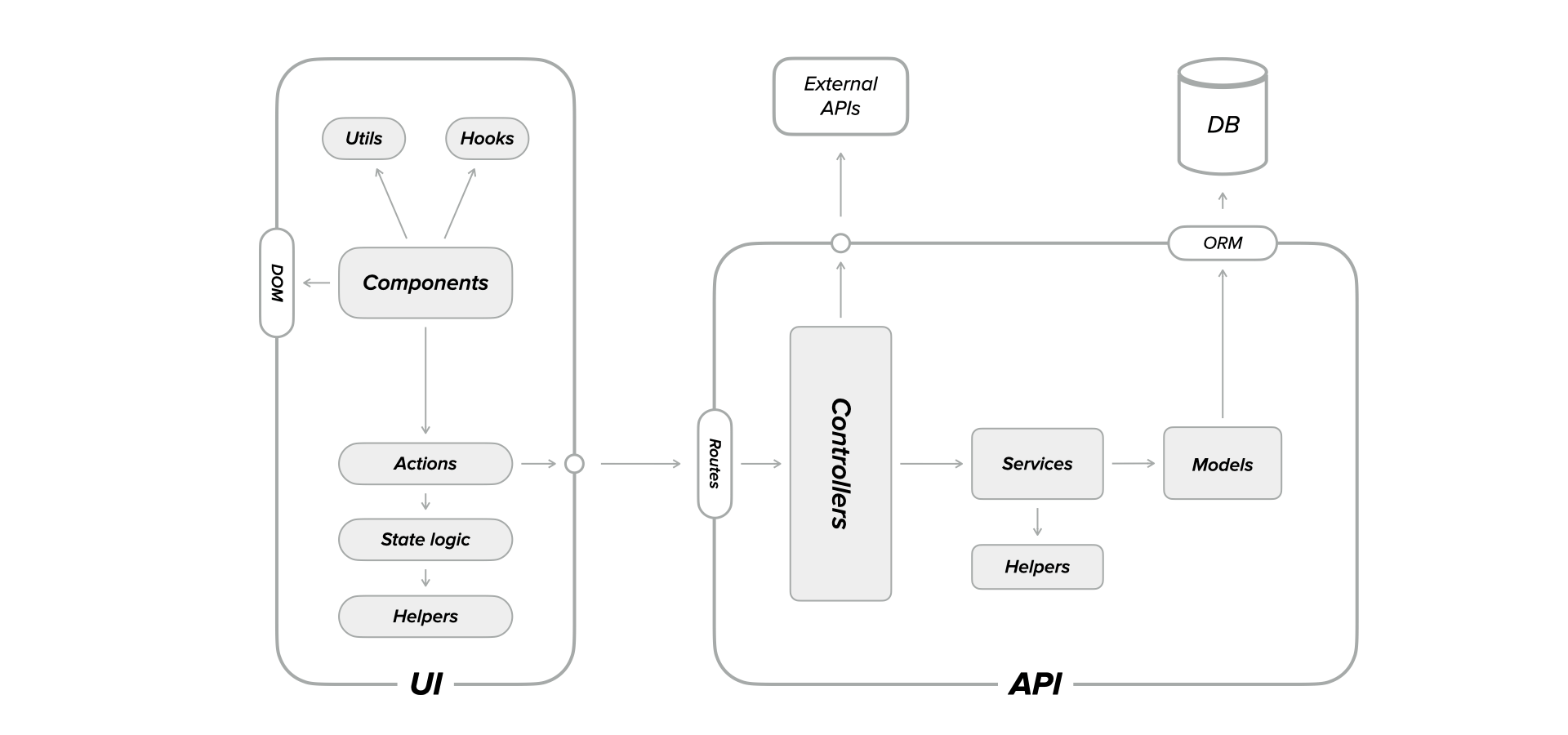
Now that we've covered the tools I'm working with let's jump into their actual usage and debate various testing approaches.
Unit testing
The most simple, easy, and fast testing method is, by far, unit testing. We take small pieces of code, execute them in isolation, outside the application, and assert their expected behavior.
What do I usually unit test?- Pure functions and class methods that contain logic, such as if/switch statements, loops, ternaries, regular expressions, etc.
- Business logic containing core behavior, extracted as pure functions.
- Utility/helper functions that are reused by multiple consumers.
- State management logic, regardless of whether using Redux,
useReducerhook, MobX, or any other approach. - Services that are reused across the application.
- Trivial pure functions that have limited or no logic at all.
- Non-reusable functions, especially if they can be tested indirectly at a higher level, like integration or end-to-end.
- Code that performs HTTP requests and side-effects, like Redux actions or Container components, as they usually require a lot of mocking and stubbing. End-to-end tests generally cover this code.
- Functions that transform data structures without any particular logic, which are type-checked by TypeScript.
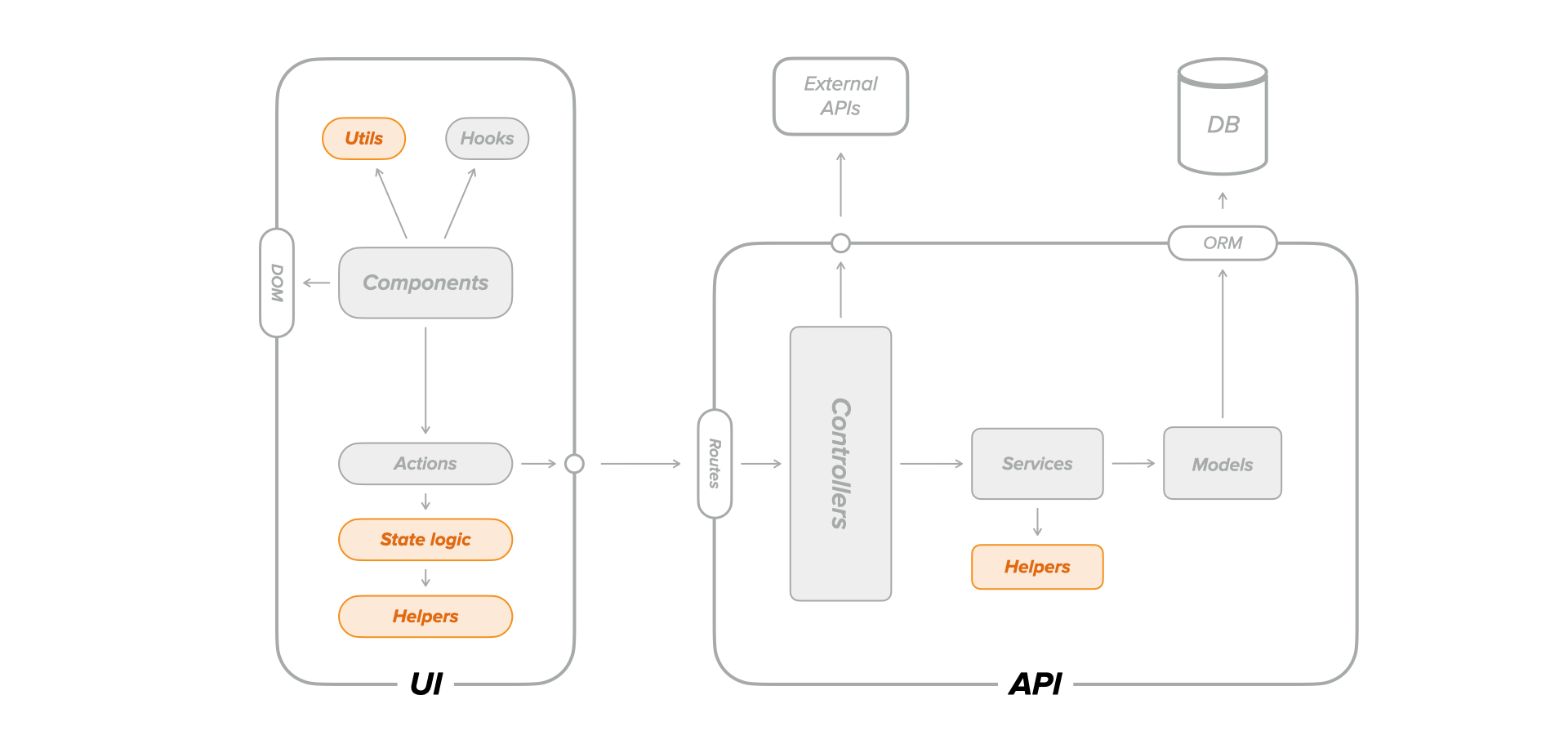
Unit testing is a powerful option because of its high execution speed, setup and usage simplicity, and consistency in results. In addition, it's super helpful during development, as it enables fast development iteration cycles.
However, all the above benefits also come with a set of limitations:
- Unit tests are isolated, meaning we only assert that individual pieces of code work as expected. Even if we test every single line of code, we have no guarantee that the application as a whole works properly when we integrate all these pieces together.
- Unit tests require advanced technical knowledge. Before writing unit tests, we must make the code testable. This usually implies several advanced techniques, such as: refactoring existing code and extracting pure functions, writing loosely coupled code, implementing inversion of control to reduce dependencies, etc.
Pure functions
In unit tests, I rarely use stubbing or mocking. Instead, I prefer to extract logic in pure functions. My reasoning is that since unit tests are all about testing code in isolation, why not isolate the code first? Pure functions are much easier to test, besides being a good general practice as well, because they are also easier to reuse.
On the other hand, using impure functions require stubbing if we want to isolate the system under test from its dependencies. This practice couples the tests with the implementation details, making tests more fragile. Any simple refactoring of the source code, such as renaming a stubbed function, would result in a false negative, failing the test even if there's nothing wrong with the actual implementation.
Before we move on to the next chapter, it's worth mentioning that unit tests are equally relevant to Front-end and Back-end. Next, we'll cover specific tests that apply to Back-end only.
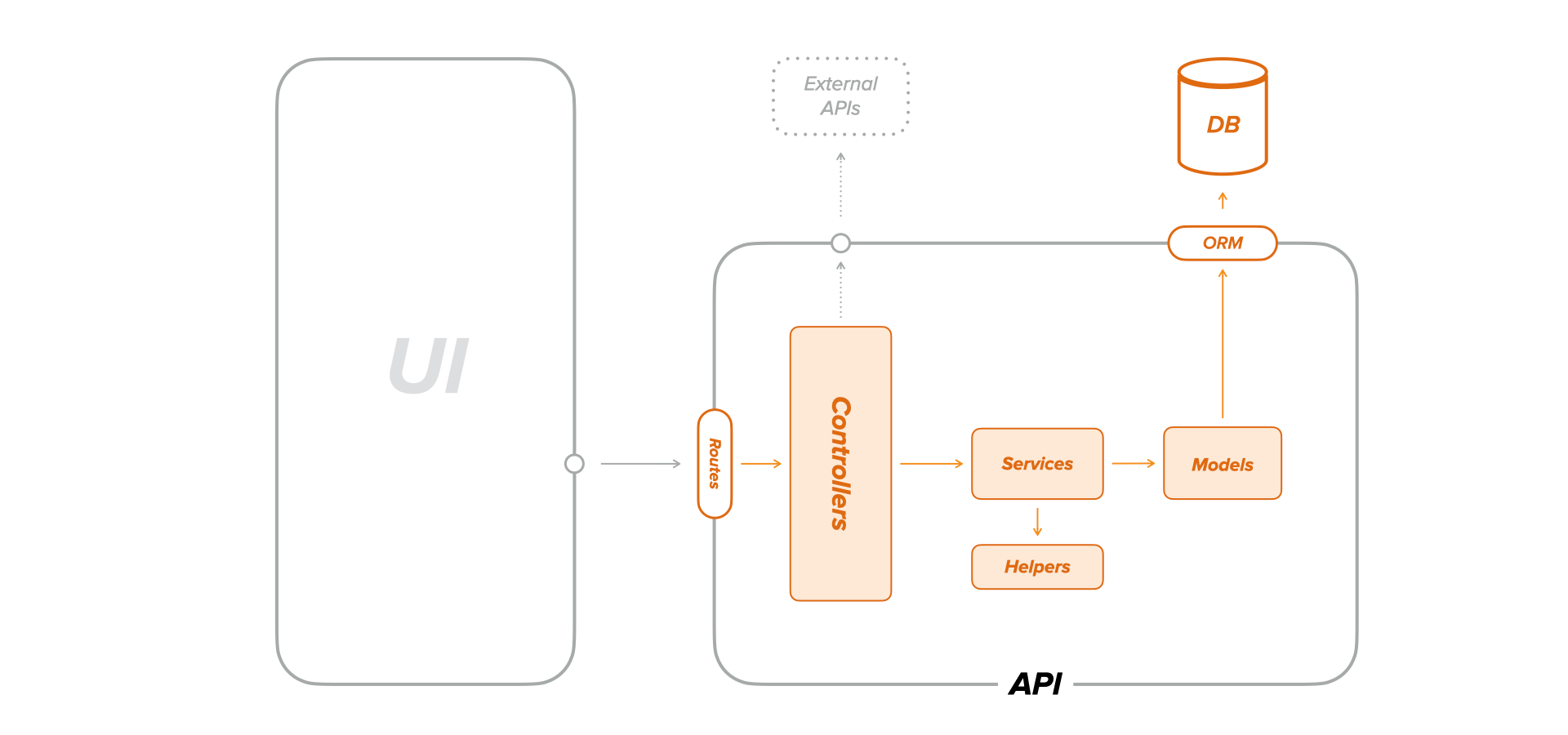
API endpoints testing
As we've previously seen, unit tests enable us to assert only isolated code. However, an actual endpoint will surely contain code non-trivial to isolate. Furthermore, endpoints often query and update one or more databases as well.
I prefer to test any server-side code that depends on a database using an integrated approach. I don't see any value in mocking or stubbing the database server.
However, to perform integration tests with the database, we need additional setup:
- First, we need to start the database server before executing the tests.
Dockerfilesare an excellent method to encapsulate the initialization of all the required servers. It's important that we use a different database for testing than the one used for development. - Second, it's mandatory to separate the
appandserverfiles. Theappfile should contain the API setup, including routes, controllers, and middleware. Theserverfile, on the other hand, should include the network layer configuration, HTTP server setup, port, etc. - Third, we have to connect the application to the test database. We can use
.envfiles to define the host, port, and DB credentials. Alternatively, if the credentials are stored in the cloud, using some secret manager, we could easily stub them. - Fourth, we need to clean up previous data and recreate the database tables before each test, so we always start from a clean state. Using an ORM like Sequelize is straightforward as calling
sequelize.sync(), which automatically creates empty tables for all loaded models. - Lastly, we have to call the API routes and assert the response. Supertest allows us to emulate HTTP requests to our endpoints without building and deploying the application.
import request from "supertest";
import sequelize from "./config/sequelize";
import app from "./app";
beforeEach(async () => {
// database server must be running
await sequelize.sync({ force: true });
});
afterAll(async () => {
await sequelize.close();
});
test("Adding an item with empty name should fail", async () => {
// simulate an endpoint request
const response = await request(app).post(`/api/item`).send({ name: "" });
expect(response.status).toEqual(400);
});
The best part of this approach is that we're integrating pretty much the entire code, testing the whole Restful API, not only isolated pieces of logic. In the case of public APIs, this approach also represents end-to-end full system tests, as we are testing the API from the consumer's perspective.
Authentication Middleware
Most API endpoints usually require authentication before processing the request. A common approach is using a middleware that validates a JSONWebToken included in the request's header after a successful login.
// middleware.ts
export function authentication(req, res, next) {
// validate JWT from request headers
if (isTokenValid(req.headers["Authorization"])) {
next();
} else {
return res.status(401).send();
}
}
Depending on the complexity of the authentication, we have two options to test endpoints that require authentication.
Fully integrate the authenticationThis approach assumes that we'll create a test user, log the user in, retrieve the JWT, and send it with each request we want to test. Integrating the authentication is valid when the previous steps don't represent a high overhead for each test.
Skip the authenticationHowever, if the authentication involves non-trivial steps, for example, using 3rd parties like Auth0, we could skip the authentication altogether. Stubbing the middleware allows us to perform requests directly, without being concerned about the technicalities of authentication.
// assume that named exports are used
import * as middleware from "path/to/middleware";
// NOTE: include this BEFORE initializing the application
jest
.spyOn(middleware, "authentication")
.mockImplementation((req, res, next) => next());
3rd parties
With complex APIs, we'll often have to deal with external services as well, like different APIs deployed from separate repositories or 3rd party APIs like logging, analytics, payment gateways, etc.
Choosing between integrating and isolating 3rd parties is simply a matter of asking: "Is the external service reliable?" I prefer to isolate the API under test and stub/mock external services in any of the following situations:
- The service isn't highly available, so it can often be offline.
- The service has high availability, but it changes frequently.
- We own the service, but the source code is deployed from a different Git repository.
- The service itself is reliable, but it calls additional services beyond our control.
Models, Services, Controllers
You might wonder "Why simulate an HTTP request and not test the controllers, services, or models directly?" To answer this question, let's take each of these layers individually.
ModelsTo be explicit, when I refer to models, especially on a Back-end API, I think about the database table abstraction, which is usually a class. Therefore, any model contains methods to manipulate database entries.
Typically, models don't encapsulate complex logic, therefore I rarely found a reason to test them directly. Furthermore, models are dependent on a database. Without integrating the tests with a real database, we don't get much value using a mocked database.
Considering all of the above, I prefer to avoid testing models directly because they get eventually tested indirectly when we test higher-level code, like services. Some exceptions to this rule include testing custom model validators or custom getters and setters.
ServicesA service is usually a reusable function that performs a specific query or command. Some services depend on models, while others don't.
If a service encapsulates complex logic, especially core business logic, or is highly reusable, it might make sense to test it directly.
On the other hand, if the service is primarily dumb, performing straightforward queries or commands, I prefer to skip testing it directly because, eventually, it will get tested indirectly by higher-level code, like routes.
ControllersIf the routes are the API's entry points, and the authentication middleware is their guardian, then the controllers represent the outer layer of the application logic. They perform several tasks:
- validate payload and user input;
- perform authorization checks;
- query or manipulate the database via services;
- call external APIs for side effects.
// routes.ts
router.post("/subscribe", subscribeController);
// controllers.ts
async function subscribeController(req, res) {
const { body, params } = req;
try {
/* ... */
res.send({ success: true });
} catch (error) {
res.status(500).send({ error: error.message });
}
}
Testing the controller per-se would save the trouble of stubbing the middleware. However, I choose not to test controllers directly because:
- I would have to mock the
resargument to assert the returned response. - I would not be able to assert the endpoint's path or HTTP verb.
Therefore, my first option is to test the routes, which will indirectly test their controller, services, and models. However, testing services directly could be more helpful or convenient in some particular situations. Choosing between the two depends on a case-by-case basis.
End-to-end system testing
To assert that an entire feature works as expected, from the UI all the way to the database, we need a different testing approach. This is where full system tests or end-to-end tests enter the scene, as we can automate entire scenarios from the user's perspective, such as:
- Create an account.
- Start a free trial.
- Purchase a subscription.
- Upgrade your subscription.
When a scenario passes an end-to-end test, we should be confident that it would work as expected for actual users as well.
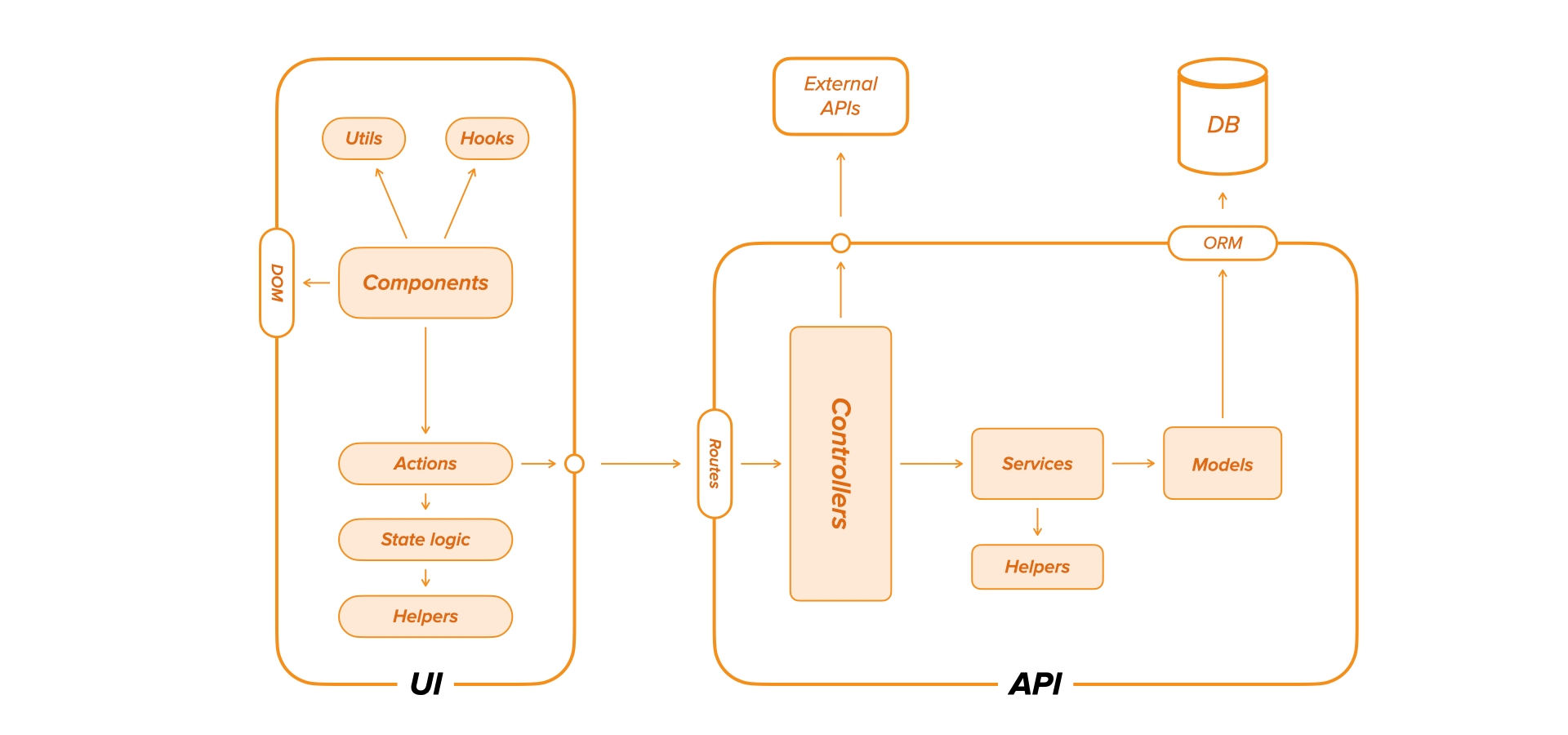
Now, the biggest problem with end-to-end tests is also their biggest benefit. Integrating the entire system, including UI, APIs, databases, 3rd parties, etc., means that everything has to be up and running to execute the tests. That's why a preferred approach to run these tests is post-deployment. Alternatively, using Dockerfiles helps run the entire system on our own computer and execute end-to-end tests locally.
Test-only API endpoints
With Cypress, besides visiting URLs and clicking buttons, we can also perform custom HTTP requests using cy.request(). We found this to be useful in 2 different scenarios:
- Activate new registered Auth0 accounts. During most tests, we create new accounts to start from a clean state. However, to login into the account, we send an activation link by email, which is cumbersome to access during an E2E test. But, we could expose a test-only endpoint that returns the latest registered account, call it from our test, get the response, and visit the URL to activate the account.
- Automate long and repeating fixture setup. Some tests require lots of steps only for setting the test fixture, which can take a long time. However, we can shortcircuit this lengthy process by exposing a custom API endpoint that performs all the setup at once without the need to click and fill forms in the UI.
Atomic test executions
During end-to-end tests, we'll often need to add new data. However, since E2E tests are fully integrated, adding new data will perform write operations on the database. Therefore, ensuring that multiple test executions render the same result is not trivial.
To illustrate the problem, consider a trivial example, having a test that performs the following operations: we add 1 item and assert 1 item exists.
False negative exampleIf the implementation is correct, the first test execution will pass as expected. However, the second test execution will incorrectly fail, as we'll have 2 items instead of 1: one from the previous test execution and another from the second.
False positive exampleThe first test execution passes as expected. Before the second execution, we brake the implementation, expecting the test to fail. However, the second test execution will incorrectly pass, as we'll already have 1 item from the previous execution.
Therefore, to ensure atomic tests execution, there are different approaches we can take:
Resetting the database before each test. Always starting from a clean state will ensure that all test executions are atomic. One test execution will never influence the other. We can implement this approach using custom test-only endpoints previously discussed.
beforeEach(() => { cy.request("/path/to/cleanup-endpoint"); });Adding and asserting unique values. Sometimes we might be unable to reset the database, regardless of the reason. Alternatively, we can generate unique data for each test and assert specifically on that unique data. For example, we could append a hash, UUID, or timestamp.
test("adding an item", { const newItem = getUniqueText("item"); items.add(newItem); expect(items.find(newItem)).toEqual(true); }); function getUniqueText(value: string) { return `${value} ${new Date().getTime()}`; }
Compound test cases
In contrast to unit testing, where each use case is atomic, we don't always follow this principle in end-to-end tests. To get a better understanding, let's consider three trivial CRUD use cases:
- Adding an item.
- Editing an item.
- Deleting an item.
In unit tests, we would have 3 different atomic and independent tests, one for each use case. However, this independence comes with an overhead, as we'll have to add additional items before testing the edit or delete scenarios.
test("adding an item", {
items.add("item"); // 1️⃣
expect(items.size).toEqual(1);
});
test("editing an item", {
items.add("item"); // 2️⃣
items.edit("item", "item edited");
expect(items.find("item edited")).toEqual(true);
});
test("deleting an item", {
items.add("item"); // 3️⃣
items.delete("item");
expect(items.size).toEqual(0);
});
The overhead of adding additional items is generally insignificant in unit tests. However, end-to-end tests are significantly slower, taking seconds or even minutes to complete. It's not uncommon to have an end-to-end that tests the adding of an item to take a long time:
- We might work with large forms, with conditionally hydrated fields based on additional network requests. For example, populate a Cities dropdown only after selecting the Country.
- Or we might have a long prerequisites chain, requiring us to create additional entities before we reach the use case under test. For example, creating a Product and a Customer before adding the Product to the Shopping Cart for a particular Customer.
Now, waiting an extra 30 seconds, for instance, might be a manageable overhead. However, following this practice doesn't scale well in the long term, potentially increasing the extra time to tens of minutes or even hours. Therefore, we often choose to optimize end-to-end tests for execution speed, testing all 3 use cases in a single test:
test("manage an item: add, edit, delete", {
items.add("item"); // 1️⃣ add only once
expect(items.size).toEqual(1);
items.edit("item", "item edited");
expect(items.find("item edited")).toEqual(true);
items.delete("item edited");
expect(items.size).toEqual(0);
});
Yes, it is a trade-off, and we're consciously making it.
UI components testing
Even though end-to-end tests seem to be the holy grail of testing user interfaces, we often feel the need to perform isolated UI tests. Some UI components are simply not suitable for testing during end-to-end tests. Such scenarios include components that:
- are cumbersome to setup using the UI, for example, involving multiple different user accounts;
- need complex stubbing with relations between various entities due to permissions rules;
- require easier debugging by narrowing the code surface, considering that a failing end-to-end test rarely points to the problem.
Taking the component out of the application, passing it directly the required data, and bypassing any outside application logic, makes testing much more convenient.
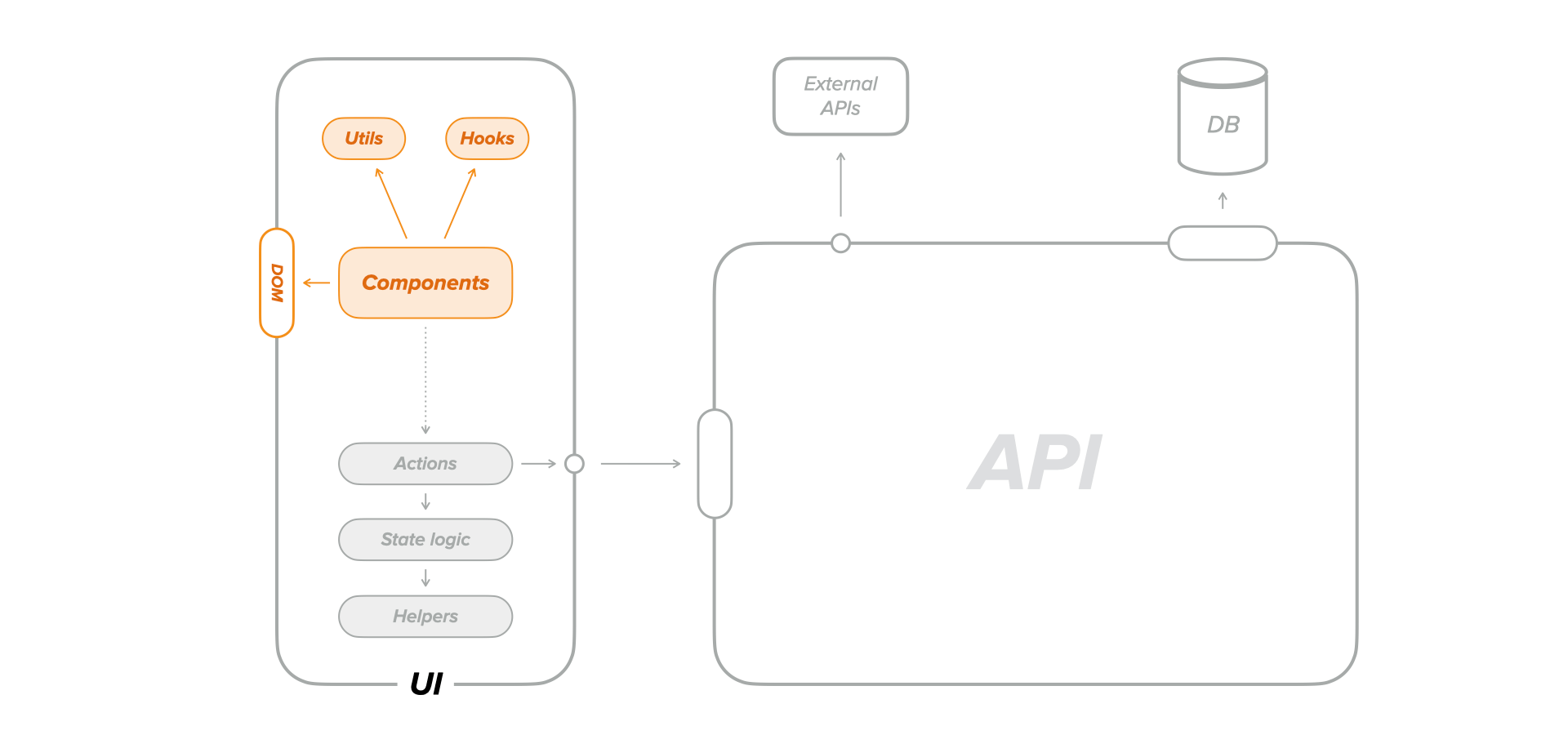
Dumb components
Let's start with the most simple components, the ones that receive some props and display some markup and styles based on the props combination. They might encapsulate some behavior, but they don't have side effects or read global state.
Reusable componentsI use Testing Library to render components in a virtual DOM whenever they encapsulate fairly complex logic, which dictates what content gets rendered.
Non-reusable componentsI usually prefer to avoid testing non-reusable components that are used on a single screen. However, if they prove critical for the feature they serve, their behavior could be easily covered at a higher level, such as end-to-end tests.
React hooks
Custom React hooks can get quite complex, especially when implementing state management with useReducer and useContext. @testing-library/react-hooks is a simple utility allowing us to test hooks easily without wrapping them inside a React component.
It's worth noting that it's debatable whether it's better to test a hook directly using a unit test or indirectly during an end-to-end test. We always make decisions on a case-by-case basis.
Browser integration
Rendering components in a virtual DOM is fast and straightforward, as it only requires Node.js. However, using a fake DOM has notable limitations:
- We cannot perform any DOM layout calculations;
- We cannot manipulate scrollbars or subscribe to scroll events, etc.
Cypress recently added support for isolated component testing in a real browser, providing the best of both worlds: integration with the browser and isolation from the application.
To conclude, there is no holy grail, a single all-in-one approach to cover all our needs. End-to-end tests provide the highest confidence level. However, they take a long time to execute, encourage a slow development iteration cycle, and integrate many dependencies, making them flaky. Lastly, a failing end-to-end test is hard to debug, as the system is treated like a black box.
Therefore, more granular and white-box tests, like unit or integration, complement the missing pieces of having a complete testing suite.