Most user interfaces work with data provided by an HTTP server, usually a RESTful or a GraphQL API. During development, there are various methods to connect these interfaces with their corresponding APIs. The ones that I've used so far are:
- connecting to a remote server;
- setting up a local environment;
- configuring a local fake API.
Let's explore each of them in more detail to discover their strong points and limitations.
Remote development server
Connecting to a remote development server is probably the most convenient method for UI/Front-End developers because it requires zero effort on their side. The entire effort relies on the infrastructure team, which has to deploy the API on a secured public URL.
It's important to understand that this lack of effort also means a lack of flexibility. We're relying solely on external resources beyond our control.

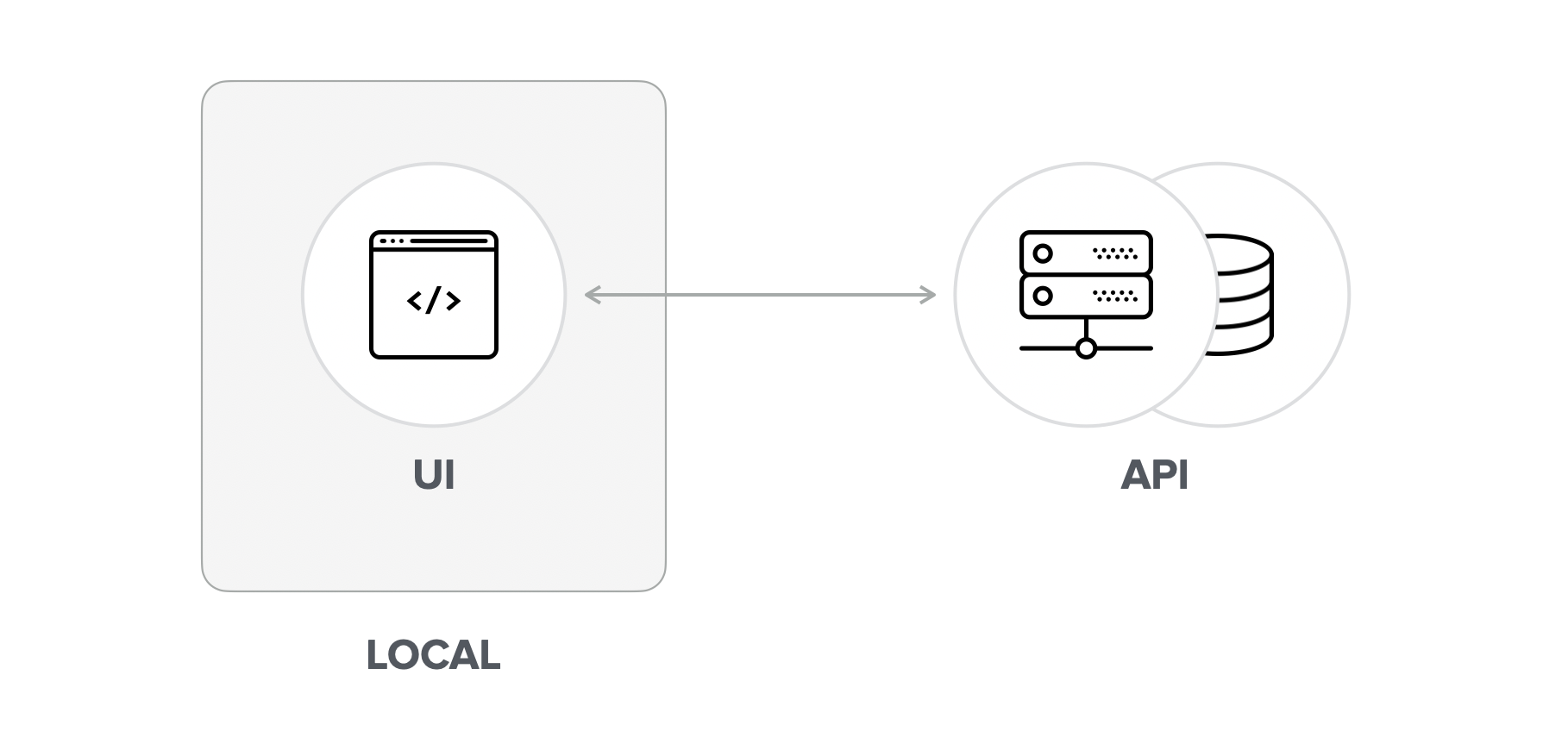
It doesn't get any easier than this. The only thing that we need to do as UI developers is to point the outgoing requests to the remote API address. No local setup of the API is required, allowing us to focus exclusively on the UI.
Shared dataAnother benefit is that the stored data is shared with all the team members consuming that API. Thus, everyone is working with the same application state. Furthermore, this enables easy reproduction of any use case between all team members.
Keep in mind that changing or removing any data will impact anyone using that API, so communication between team members is essential.
Infrastructure dependentOne limitation of this approach is that it's not trivial to deploy different branches on the same server. Changing the deployed branch would be confusing, especially with large teams.
In addition, supporting multiple deployed branches at once requires additional servers and infrastructure management.
Doesn't work offlineLast but not least, a stable internet connection is mandatory during development. Unfortunately, this also means that we cannot get any work done if the development server is offline.
Local setup
To overcome the limitations of a shared development server, we could run the entire API locally. Using a containerization method, like Docker, made this a lot easier, allowing us to have complex infrastructure running locally in just a few minutes.
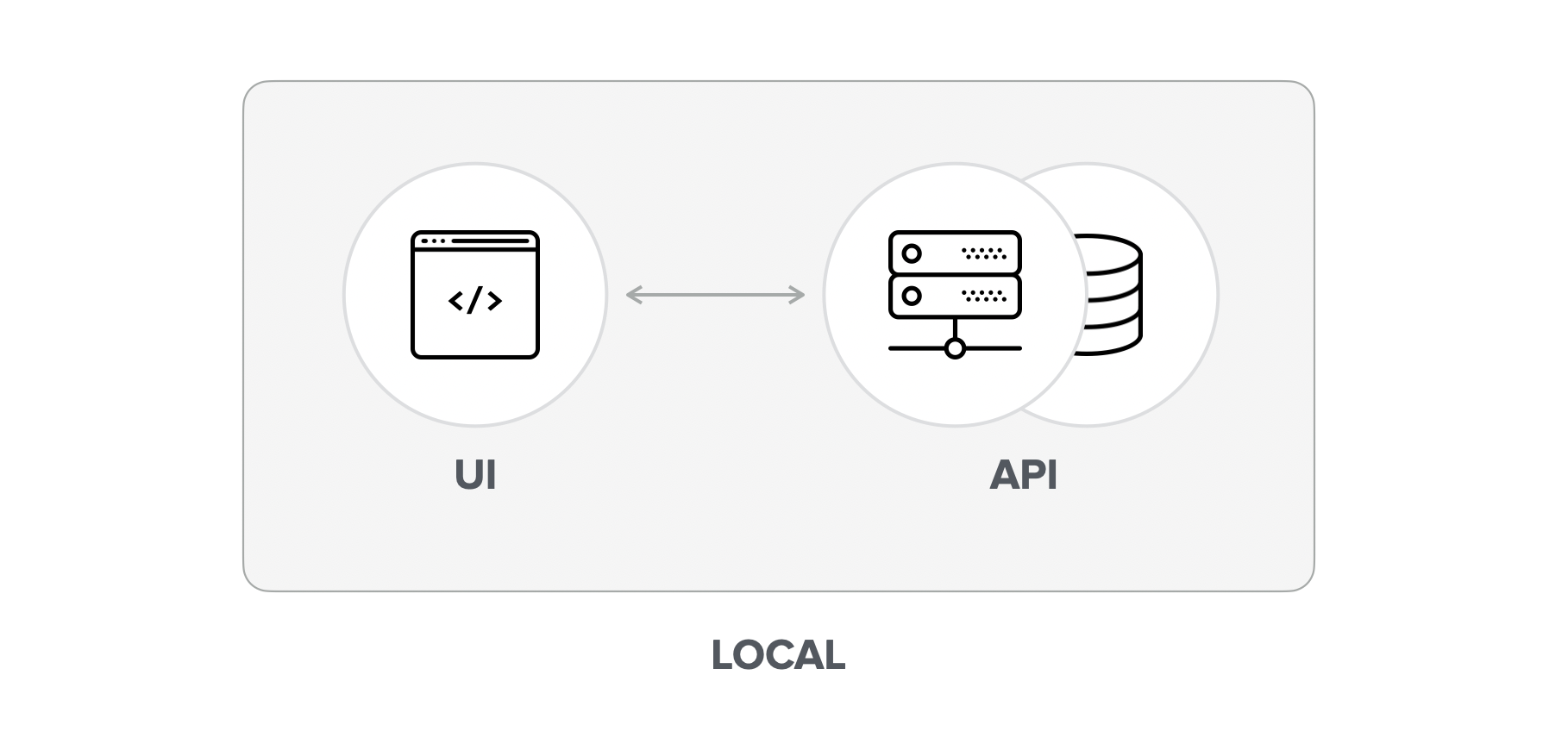
Since we're running everything locally, an internet connection is not required.
Easily switch branchesWe have complete control over the versioning system, meaning that we can easily switch to any branch or tag, enabling us to test any work-in-progress feature or reproduce bugs using previous API versions.
Cumbersome data sharingOne limitation of running the entire API locally is that we can't easily share our application state with other team members. Sharing data requires either:
- exporting the database, sending it to our colleagues, and have them import it into their API;
- or explain to them all the steps necessary to reach the desired application state.
Containerization indeed made this approach a whole lot easier, but with real-world applications, the initial setup and subsequent updates are not always straightforward:
- different operating systems usually require specific handling;
- working with certain 3rd party APIs, like payment gateways, might require mocking;
- last but not least, each team member will have to perform all the required database migrations, dependencies setup, and so on.
Fake API
A third approach is to use a fake local API to short-circuit the real API altogether. The one that I've used with success in the past is json-server, but there are many other solutions available.
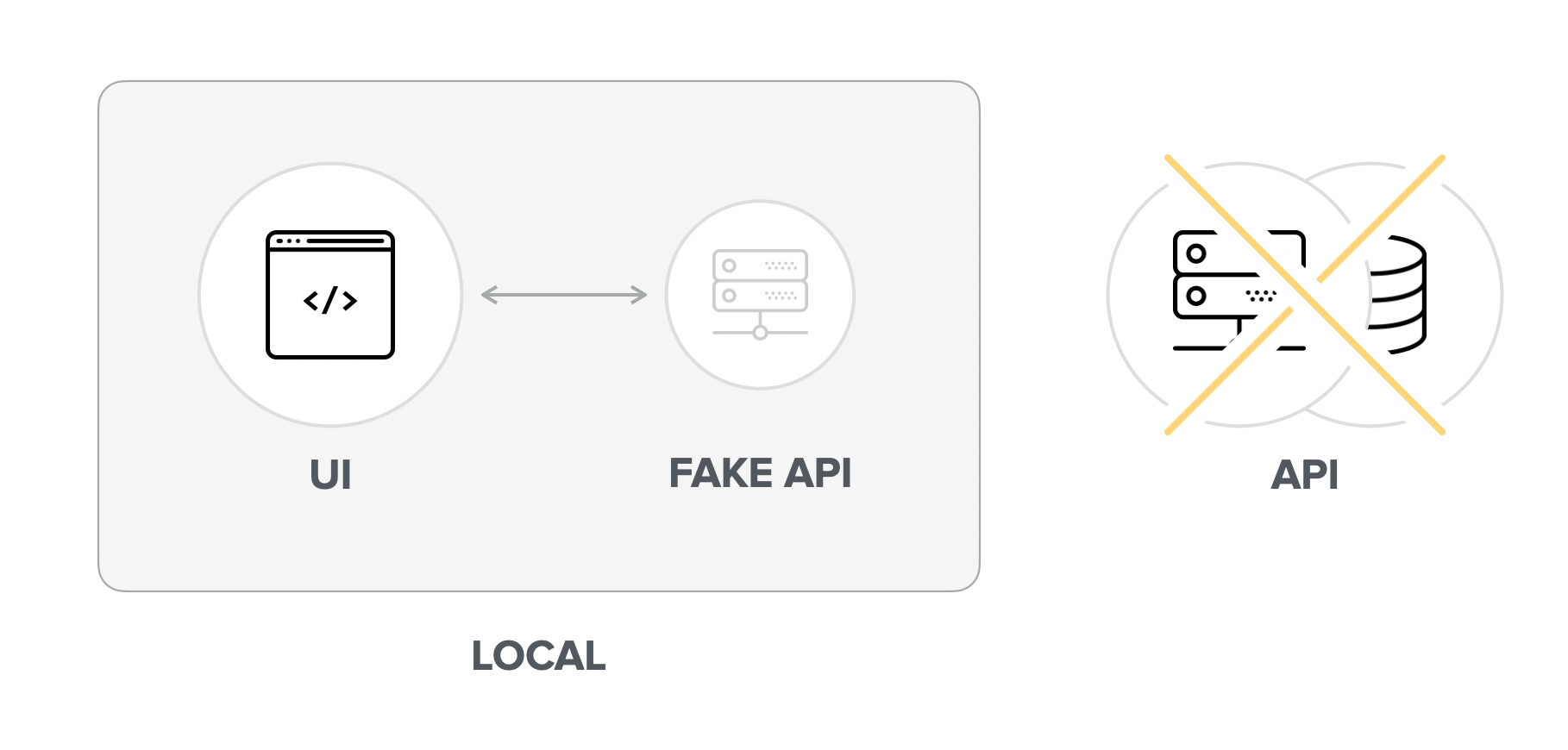
The most significant benefit of this approach is probably the lack of effort required to stub specific data. With the previous methods, we cannot directly control the endpoints' output. Instead, we have to bring the system to a particular state so that the endpoints respond with the desired result.
Having typed API requests helps a lot to ensure that we include all the required data.
Maintenance costProbably the biggest drawback is that we'll have to manually update the endpoints' response whenever the real API changes, which incurs an ongoing maintenance cost.
Without a solid collaboration between the UI engineers responsible for the fake API and the real API maintainers, this could become a severe issue.
Like any engineering problem, there is no silver bullet. None of the methods is perfect, but each of them shines in different situations:
- Integrating with a remote development server proves very convenient, especially in teams where development is split between dedicated UI/Front-End and API/Back-End developers.
- Having a local setup of the API provides a high degree of flexibility and control, useful in full-stack development, where developers work both on the UI and the API.
- Using a fake API works great for prototyping or during early development stages when we don't have a fully functioning web API. Still, it could also be helpful to bypass complex infrastructure or difficult-to-reach application states.